Build an AI Vision Assistant
🔉 Play the video above with audio!
TIP
Imagine an AI assistant that not only talks but also “sees” for you. Welcome to the era of Large Multimodal Models!
Combining Eye Tracking With AI for Assistive Applications
Unlike popular Large Language Models (LLMs), which can only interpret and interact with text, Large Multimodal Models (LMMs) are also able to understand images. This means chatbots, like GPT, can understand, describe and interpret the content of real-world scenes, including identifying different objects and how people might interact with them.
When combined with eye tracking, this holds potential for assistive technologies. For example, it could help individuals with low vision to identify the objects at which they are gazing, highlight potential hazards in their surroundings, or assist people with ALS who face significant communication challenges.
Here, we show you how to build a simple, explorative, gaze-based assistive tool using Neon or Pupil Invisible and a new LMM, GPT-4V.
What Tools Enable This
OpenAI recently unveiled a set of new APIs at their DevDay event, introducing GPT-4V, an extension of their most advanced large language model capable of understanding images. We gained access to the preview and decided to see what their model is capable of when integrated with our eye trackers. We used Neon and Pupil Invisible since they remove the barrier of calibration, making them more suitable for longer sessions and real-life scenarios and, therefore, in a good position to experiment with assistive applications.
We used the real-time API to stream scene camera video and gaze positions over the network. We grab a frame from the real-time stream and send it to GPT4-V for processing. We get back text that can be used to inform the wearer about what they were looking at or whatever we wanted to ask about the scene.
Steps
To try this demo, you'll need a Neon or Pupil Invisible eye tracker, a computer with internet access, and an OpenAI key that has access to the latest GPT-4V model.
INFO
24/06/12 Update: This script uses now gpt-4o by default.
Head to this script and follow the installation instructions.
Scene Understanding in Real-Time
Look at something in your environment and press the Space key. A snapshot with gaze overlay will be sent to GPT, and you will receive a vocal response.
The nature of the AI assistant's response will depend on the selected model. We have defined 4 modes that can be toggled with ("ASDF") keys:
A: a description of what you're gazing at.S: any potential danger.D: a guess about your intentions.F: a more detailed description of the environment.
In this initial exploration, GPT-4V was generally good at identifying what was being gazed at or trying to predict the wearer's intentions. However, it wasn't fast enough to detect immediate dangers due to network latency. The great thing about GPT-4V is that you can modify the prompts to suit your specific needs. Rapid advancements in the field suggest that we might soon see these types of models operating locally and with virtually no latency. How useful could this be? We would love to hear your feedback!
TIP
Need assistance implementing a real-time API based application? Reach out to us via email at info@pupil-labs.com, on our Discord server, or visit our Support Page for formal support options.
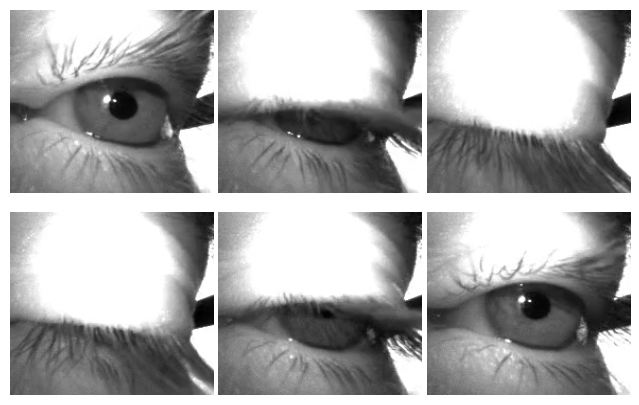
Detect Eye Blinks With Neon
Apply Pupil Labs blink detection algorithm to Neon recordings programmatically, offline or in real-time using Pupil Labs real-time Python API.
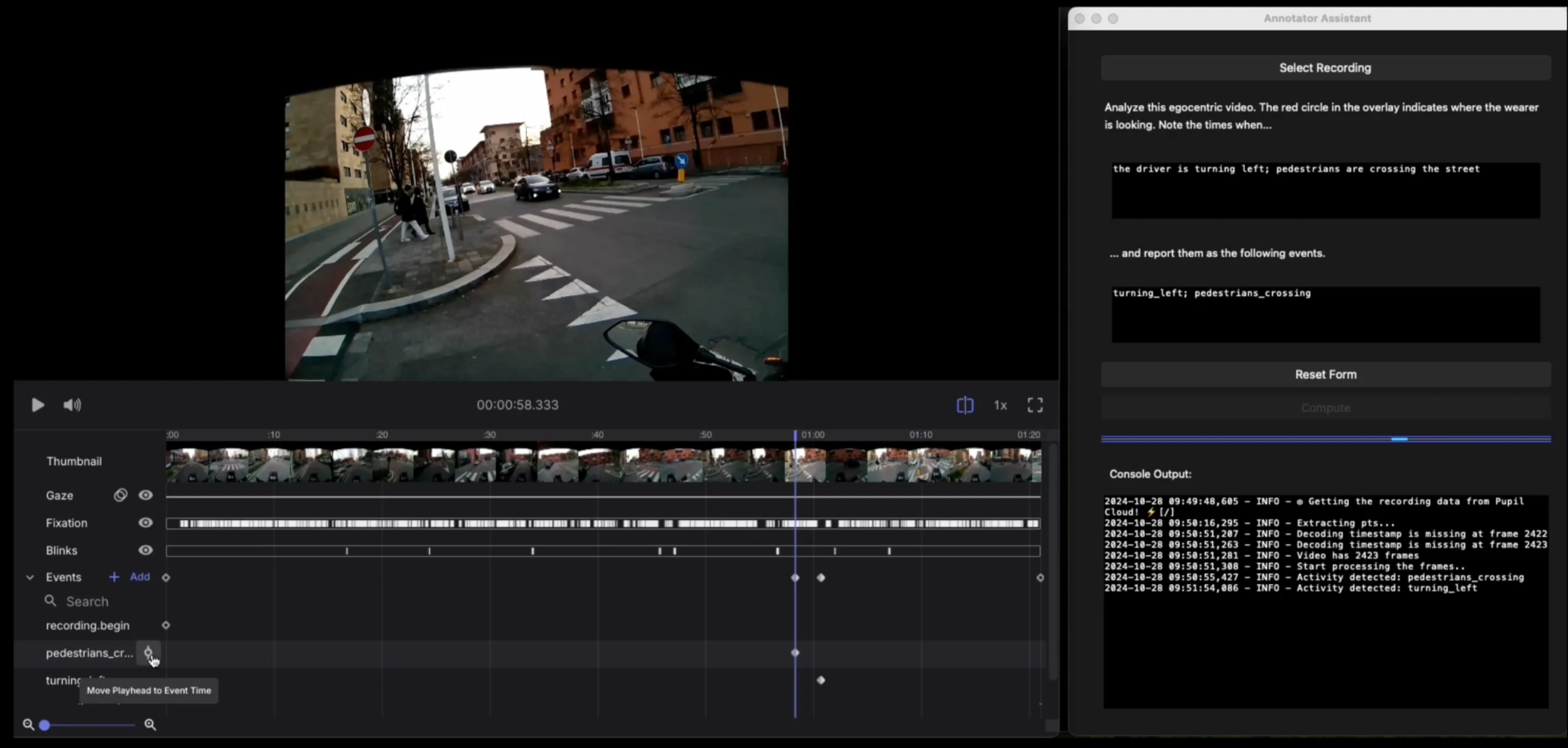
Automate Event Annotations With Pupil Cloud and GPT
Automatically annotate important activities and events in your Pupil Cloud recordings with GPT-4o.
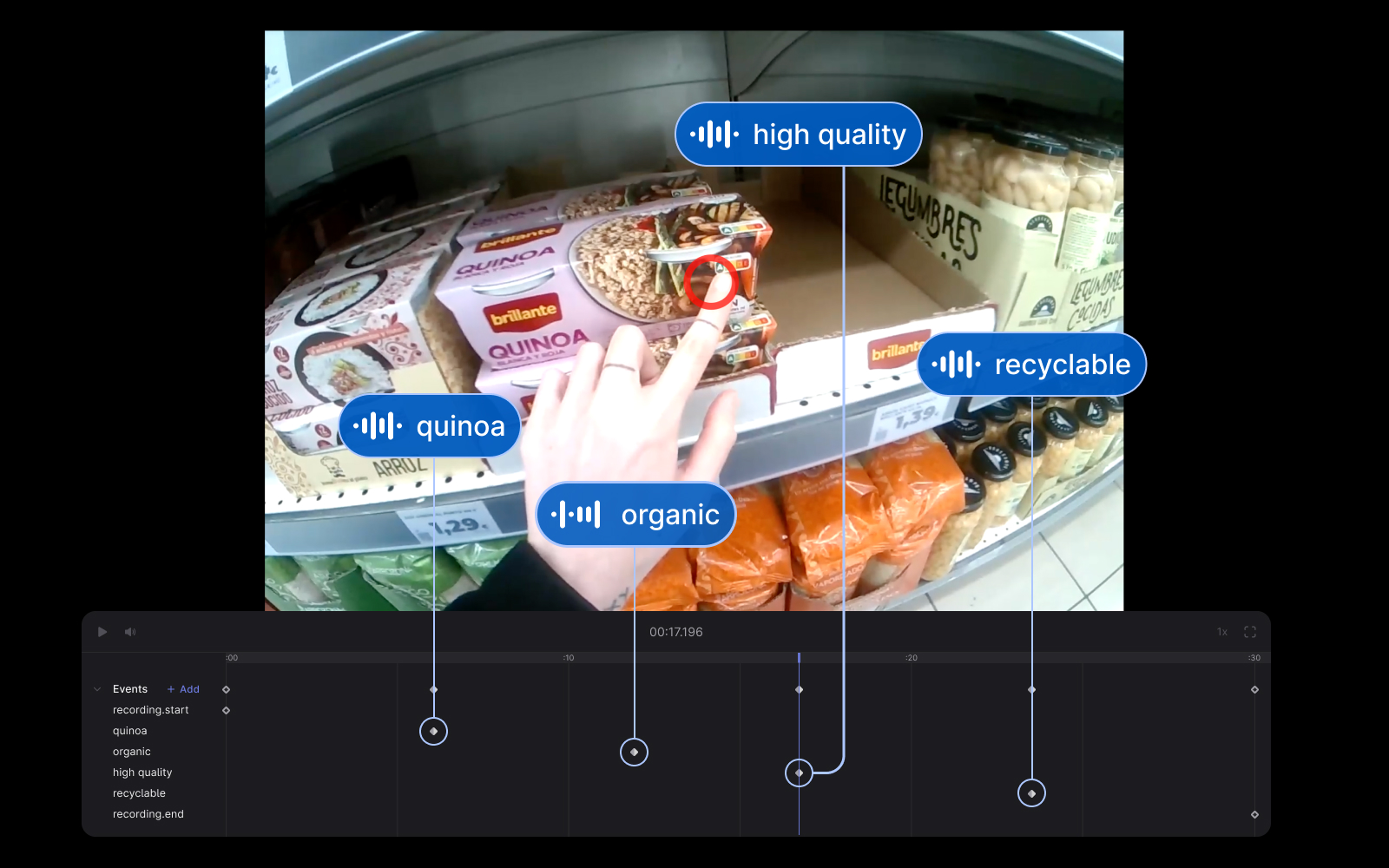
Audio-Based Event Detection With Pupil Cloud and OpenAI's Whisper
Automatically annotate important events in your Pupil Cloud recordings using Neon's audio capture and OpenAI's Whisper.